

Executive Summary
A fundamental paradox has emerged at the heart of modern software delivery. The proliferation of tools and practices under the banner of DevOps, intended to accelerate innovation, has inadvertently created environments of such staggering complexity that they now actively hinder it. Engineering teams, faced with a sprawling ecosystem of technologies, are increasingly susceptible to analysis paralysis - a state of cognitive overload that stifles decision-making and slows velocity. This report argues that the primary bottleneck in software delivery has shifted from a technological constraint to a human one, rooted in the finite cognitive capacity of developers.
This analysis begins by deconstructing the psychological underpinnings of this issue, applying established principles such as Cognitive Load Theory and decision fatigue to the daily realities of DevOps and Site Reliability Engineering (SRE). It presents quantitative evidence of the problem, detailing the "tool sprawl" and the hidden "toolchain tax" that consumes a significant portion of developer productivity. The report finds that organisations have reached a point of negative returns, where each new, unintegrated tool adds more friction than value.
In response to this systemic challenge, the report details the rise of platform engineering as a strategic discipline. It defines the Internal Developer Platform (IDP) as the core artefact of this practice - an integrated, self-service product designed to abstract away underlying complexity and provide developers with curated "golden paths" for building, deploying, and operating software. By treating internal infrastructure as a product and developers as its customers, platform engineering provides the technical foundation necessary to realise the cultural goals of DevOps and the reliability principles of SRE at scale.
Through an examination of industry data, performance benchmarks like the DORA metrics, and case studies from pioneers such as Spotify and Netflix, this report validates the effectiveness of the platform engineering model. It demonstrates a direct, mechanical link between investment in developer experience and tangible improvements in software delivery velocity and stability. Finally, I offer a pragmatic guide for implementation, addressing common pitfalls, organisational anti-patterns, and the critical importance of adopting a product-centric mindset. Ultimately, it is concluded that platform engineering is not merely a new trend but a necessary evolution in organisational design, essential for managing complexity and unlocking the full potential of engineering talent in the cloud-native era.
Section 1: The Human Factor: Deconstructing Cognitive Overload in Modern Engineering
The discourse surrounding DevOps and SRE has historically centred on tooling, automation, and metrics, often overlooking the human elements that ultimately determine the success of these initiatives.[1] While the goal is to increase speed and reliability, the practices have expanded the scope of developer responsibility to a degree that frequently pushes against the fundamental limits of human cognition. The result is a state of analysis paralysis, not born from a lack of options, but from an overwhelming surplus of them. This section dissects the psychological principles that underpin this phenomenon, arguing that the primary bottleneck in modern software delivery has shifted from the technological to the human domain.
1.1 The Anatomy of Analysis Paralysis in High-Stakes Environments
Analysis paralysis is a state of over-thinking a problem to the point that a decision or action is never taken.[2] In the context of DevOps and SRE, this state is induced by two powerful psychological forces: the paradox of choice and decision fatigue.
The paradox of choice posits that while some choice is good, an overabundance of options leads to mental exhaustion, indecision, and dissatisfaction.[3] This principle directly maps to the "DevOps Tooling Jungle," where engineers confront a dizzying array of tools for every function: container orchestration (Kubernetes, Nomad, ECS), CI/CD (Jenkins, GitLab CI, CircleCI, GitHub Actions), observability (Prometheus, Datadog, ELK Stack, Zabbix), and cloud providers (AWS, Azure, GCP).[4, 5, 6] When every team is free to choose its own stack, each developer is forced to become a systems integrator, constantly evaluating, configuring, and connecting a fragmented ecosystem. This surplus of choice paralyses action, as the mental effort required to make an optimal, or even a "good enough," decision becomes prohibitively high.[3]
This leads directly to decision fatigue, the scientifically documented deterioration in the quality of decisions made by an individual after a long session of decision-making.[7, 8] Software development is an inherently decision-heavy discipline, involving choices about architecture, algorithms, and logic.[9] The DevOps model adds a significant layer of operational and infrastructural decisions to this workload. When engineers spend their limited daily reserve of mental energy on trivial choices - which version of a library to use, how to configure a security policy, which logging format to adopt - their capacity for making high-quality, high-impact decisions on core product features is severely depleted.[7, 8] This fatigue manifests in several ways detrimental to project velocity and quality, such as procrastination, decision avoidance, and defaulting to familiar but suboptimal solutions simply to end the decision-making process.[7, 8]
1.2 Applying Cognitive Load Theory to the DevOps Toolchain
To formalise the analysis of this mental strain, one can apply Cognitive Load Theory (CLT), a framework from educational psychology developed by John Sweller that has gained significant traction in software engineering.[1, 10] CLT describes the mental effort required to process information and perform a task, categorising it into three distinct types.[10]
- Intrinsic Cognitive Load: This is the inherent difficulty of the subject matter itself. For a developer, this is the complexity of the business problem they are trying to solve or the algorithm they are designing. This is the "good" complexity where engineers should invest their mental energy.[10]
- Extraneous Cognitive Load: This is the mental effort wasted on navigating inefficient processes, poorly designed interfaces, or irrelevant information. It is the "bad" complexity that does not contribute to task completion or learning. In DevOps, this is the effort spent deciphering a cryptic pipeline failure, manually correlating logs from three different systems, or navigating the labyrinthine console of a cloud provider to provision a resource.[1, 10]
- Germane Cognitive Load: This is the effort dedicated to processing information and constructing long-term mental models, or "schemas." A well-designed system promotes germane load by presenting information and workflows in a clear, consistent, and logical manner, facilitating deep learning.[10]
The central problem in many DevOps environments is an excess of extraneous cognitive load, which consumes the mental bandwidth that should be allocated to intrinsic and germane load. Academic research has identified several key contributors to this overload:
- Costly Context Switching: Modern developers are expected to juggle coding, code reviews, debugging, incident response, and infrastructure management.[1] Each switch between these disparate tasks incurs a significant cognitive penalty as attention must be reoriented. Studies published in journals like IEEE Software and ACM Queue have demonstrated that the cost of these context shifts is cumulative, leading directly to increased error rates, delayed task completion, and decreased job satisfaction.[1] A survey found that 97% of developers report that toolchain sprawl forces this kind of constant, productivity-killing context switching.[11]
- Fragmented Toolchains: The promise of DevOps automation is often undermined by the reality of poorly integrated tools. When version control, CI/CD platforms, monitoring dashboards, and security scanners do not communicate seamlessly, developers are forced to become manual correlation engines. They must navigate multiple user interfaces, cross-reference data across different dashboards, and mentally "stitch together" a complete picture of system state. This activity is a pure form of extraneous cognitive load, wasting valuable time and mental energy that could be spent resolving the actual issue.[1]
- Alert Fatigue: The constant stream of information, notifications, and alerts from complex, distributed systems can overwhelm an engineer's capacity for rapid, accurate decision-making, particularly during high-pressure incident response scenarios. Add into this Slack, Teams, Telegram, Jabber - or whatever else you're using for direct messaging from anyone into your developer time and it's easy to see that this cognitive overload impairs judgment, increases the likelihood of human error, and ultimately degrades overall system reliability.[1]
The following table provides concrete examples of how different DevOps activities map to the three types of cognitive load, illustrating the sources of friction that platform engineering aims to eliminate.
| Cognitive Load Type | DevOps/SRE Activity Examples |
|---|---|
| Intrinsic (Essential Complexity) | - Designing the architecture for a new microservice. - Writing the business logic for a new product feature. - Developing a complex database query to generate a business report. - Understanding the core systems design principles (e.g. distributed system like Paxos or Raft). |
| Extraneous (Accidental Complexity) | - Manually looking up IP addresses and credentials to SSH into a server. - Correlating a spike in CPU metrics in one tool with application error logs in another. - Deciphering a bespoke, undocumented CI/CD pipeline script written by a former employee. - Navigating multiple cloud provider UIs to provision a consistent set of resources. - Debating which of five approved logging libraries to use for a new service. |
| Germane (Productive Learning) | - Learning the standardised service creation template provided by an Internal Developer Platform. - Understanding the common observability patterns established by the platform team. - Internalising the organisation's "golden path" for deploying a containerised application. - Building a mental model of how the platform's self-service capabilities map to underlying infrastructure. |
Table 1: Mapping Cognitive Load Types to DevOps Activities
1.3 The Path to Burnout: The Organisational Cost of Cognitive Overload
The cumulative effect of sustained high cognitive load and decision fatigue is not merely a temporary dip in productivity; it is a direct pathway to developer burnout. Burnout is a state of emotional, physical, and mental exhaustion caused by prolonged and excessive stress, and it represents a significant organisational risk.[12] The "always-on" culture and high stakes of maintaining production infrastructure contribute to the prolonged, excessive cognitive load that can lead to this condition.[12, 13]
The consequences of burnout are severe and far-reaching. They include decreased morale and motivation, which can poison team culture and increase attrition - in significant cases, it can even lead to a great percentage of employees taking unplanned time-off. Cognitively overwhelmed teams exhibit slower problem resolution times, as their capacity for clear, creative thinking is diminished, leading to project delays and missed deadlines.[12] Perhaps most critically, burnout erodes team cohesion and communication; individuals become narrowly focused on managing their immediate tasks and alerts, losing the capacity for effective collaboration that is the cornerstone of the DevOps philosophy.[1] Ultimately, a state of chronic cognitive overload directly undermines the very reliability and velocity it is meant to support. The systemic paradox is that the pursuit of velocity through unmanaged developer autonomy has created environments whose complexity exceeds the cognitive limits of the very individuals meant to be empowered. The bottleneck has shifted from technology to human cognition, necessitating a new approach that manages this complexity at a systemic level.
Section 2: The Catalyst for Paralysis: A Quantitative Analysis of Toolchain Complexity
The cognitive pressures described in the previous section are not abstract theoretical concerns; they are the direct result of a tangible and measurable phenomenon in modern software organisations: the uncontrolled proliferation of tooling. This section provides the empirical data to support the diagnosis of cognitive overload, quantifying the scale of what is commonly known as "tool sprawl" and measuring its direct, negative impact on developer productivity, organisational risk, and business velocity.
2.1 The State of the Modern Toolchain: "Tool Sprawl" by the Numbers
"Tool sprawl" is the condition that arises when an organisation accumulates an excessive number of disparate, poorly integrated tools to perform similar or adjacent functions.[5] This is rarely the result of a deliberate strategy. Instead, it is the cumulative effect of years of well-intentioned but uncoordinated tactical decisions, where individual teams adopt point solutions to solve immediate problems, leading to a fragmented and complex technological landscape over time.[5, 11]
Industry surveys provide stark, quantitative evidence of the scale of this problem:
- A 2020 DevOps Trends survey conducted by Atlassian and CITE Research found that, on average, organisations are using 10.3 distinct toolchains to manage their software development lifecycle.[14, 15]
- A 2023 survey of 300 IT professionals, conducted on behalf of Port, Inc., revealed that developers navigate an average of 7.4 different tools simply to build their applications.[16]
- GitLab's 2024 Global DevSecOps Survey corroborates this and shows the trend is consistent, finding that over half of DevOps teams are juggling six or more tools, with a significant 13% managing a staggering 10 to 14 different tools.[17]
This complexity is not just a nuisance; it is a primary impediment to progress. The 2023 DevOps Automation Pulse report found that 53% of IT practitioners cite toolchain complexity as a key barrier to adopting further automation, indicating that the very tools meant to enable efficiency are now preventing it.[18]
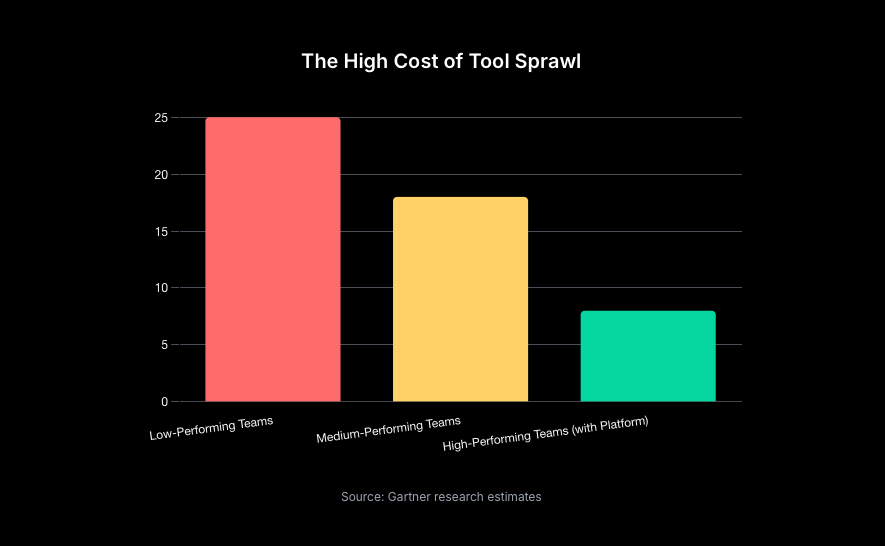
2.2 The Hidden "Toolchain Tax": Quantifying the Productivity Drain
The direct consequence of tool sprawl is a hidden but substantial "toolchain tax" - the cumulative overhead of maintaining, integrating, and navigating this complex web of tools.[17] This tax is paid daily in the form of lost developer productivity, and its magnitude is alarming.
Survey data provides a clear accounting of this productivity drain:
- The Port, Inc. survey found that an astounding 75% of developers lose between 6 and 15 hours every week due to the friction and context switching caused by tool sprawl.[16] This translates to one to two full workdays per developer, per week, spent wrestling with tools rather than writing code.
- A Harness webinar survey revealed that 97% of developers report that this sprawl forces constant, productivity-killing context switching.[11]
- The GitLab survey offers a different but equally damning perspective: 78% of DevOps professionals spend at least a quarter of their day on toolchain maintenance and integration. For over 27% of respondents, this tax consumes between 50% and 74% of their entire workday.[17]
These figures reveal a clear pattern of diminishing and, ultimately, negative returns on tooling investment. The initial productivity gains from adopting a new tool are eventually eclipsed by the mounting costs of integration, context switching, and maintenance. This suggests that many organisations have passed a critical tipping point where adding more point solutions actively harms productivity and business velocity. The problem is not a lack of tools, but a fundamental lack of a coherent, integrated system. This creates a significant market inefficiency where companies are spending more on their toolchains only to see developer output decline. The solution, therefore, cannot be yet another point tool; it must be a systemic one that addresses the integration tax itself.
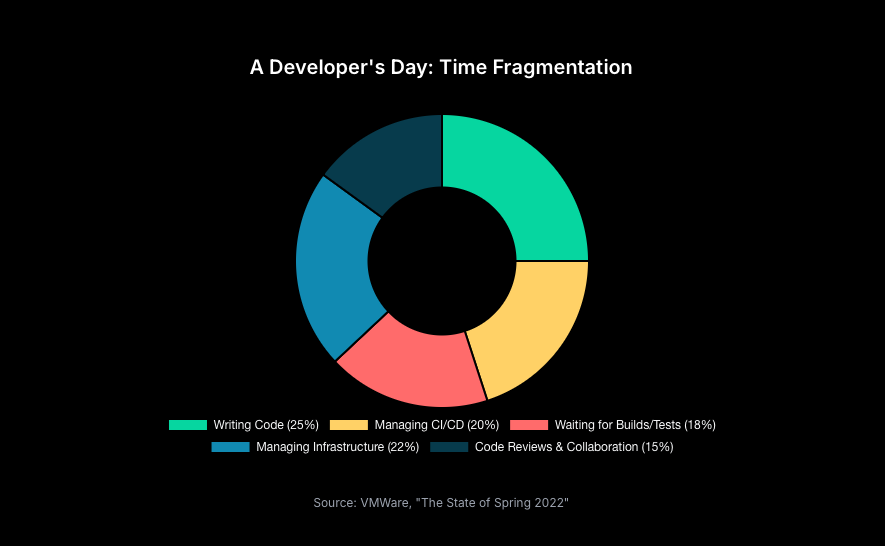
2.3 The Compounding Effect on Security, Compliance, and Reliability
The impact of a fragmented toolchain extends beyond lost productivity, creating systemic risks that undermine security, compliance, and reliability. A disparate ecosystem prevents the consistent application of organisational standards and guardrails, leading to a number of critical challenges.
- Inconsistent Security and Reliability: Without a standardised way to implement security policies or reliability best practices, each team is left to its own devices. This results in a patchwork of configurations, increasing the likelihood of security vulnerabilities and reliability issues going undetected. For example, one team might use a robust security scanner in their pipeline, while another might not, creating blind spots in the organisation's overall security posture.
- The "Multiple Panes of Glass" Problem: When security data, systems performance data, and application logs reside in separate, uncorrelated tools, it becomes exceedingly difficult to gain a holistic view of the system's health.[4] During a security incident or a production outage, engineers are forced to manually jump between different dashboards, attempting to connect disparate pieces of information. This significantly slows down incident response and makes root cause analysis a frustrating exercise in manual data correlation.[1]
- Increased Operational Overhead and Risk Surface: Each new tool in the chain introduces its own lifecycle for development, testing, versioning, and deployment.[4] This not only increases the maintenance burden on engineering teams but also expands the surface area for configuration errors, integration failures, and security vulnerabilities.
- Erosion of Trust: The culmination of these issues is a profound lack of confidence in the systems themselves. The Port, Inc. survey found that over half (55%) of IT professionals do not trust the veracity of the data presented in their various tool repositories.[16] When engineers cannot trust their tools, they are forced to spend more time on manual verification, further slowing them down and reinforcing the cycle of analysis paralysis.
In aggregate, the quantitative data paints a clear picture: the unmanaged growth of the DevOps toolchain is the primary catalyst for the cognitive overload and analysis paralysis experienced by engineering teams. It imposes a crippling productivity tax and introduces systemic risks that directly contradict the core goals of speed and stability.
Section 3: The Strategic Response: The Principles and Practice of Platform Engineering
In response to the escalating crisis of cognitive overload and toolchain complexity, a clear definition of the platform engineering discipline has emerged and is rapidly gaining prominence. This approach represents a strategic and systemic solution, shifting the focus from managing a chaotic collection of tools to providing a cohesive, product-centric foundation for developers. This section defines the principles and practice of platform engineering, introduces its core artefact - the Internal Developer Platform (IDP) - and clarifies its synergistic relationship with the established philosophies of DevOps and SRE.
3.1 Defining the Discipline: The Rise of the Internal Product
Platform engineering is formally defined as "the discipline of designing and building toolchains and workflows that enable self-service capabilities for software engineering organisations".[19] It is a practice born from DevOps principles that seeks to improve developer experience (DevEx) and accelerate time-to-value by providing a secure, governed, and self-service framework for engineering teams.[20] The influential technology research firm Gartner predicts that by 2026, 80% of large software engineering organisations will have dedicated teams for platform engineering, underscoring its strategic importance.[20, 21]
The central artefact created and maintained by a platform team is the Internal Developer Platform (IDP). An IDP is an integrated product that bundles the operational necessities for the entire lifecycle of an application, presenting them to developers through a simplified, self-service interface.[19, 22] It is the tangible implementation of the platform engineering philosophy.
Within the IDP, teams collaborate to curate and build "Golden Paths" (also referred to as "paved roads"). A golden path is an opinionated, well-documented, and officially supported workflow that represents the most efficient, secure, and compliant way to accomplish a common engineering task, such as creating a new microservice, provisioning a database, or deploying an application to production.[1, 19, 23, 24] By following these pre-configured paths, developers are freed from making countless low-level decisions and can move forward with confidence, knowing that best practices for security, observability, and scalability are already baked in.[18]
The most significant innovation of platform engineering is not technical but organisational and philosophical. It mandates that an organisation treat its internal infrastructure and tooling as a product and its developers as its customers. This product-centric approach is the fundamental differentiator from traditional, ticket-driven IT and operations models. Where a traditional infrastructure team is often managed as a cost centre measured by uptime and ticket resolution times, a platform team operates like a product team. This requires them to engage in continuous user research with their developer customers, build and prioritise a roadmap based on their most significant pain points, and measure success through metrics like adoption, user satisfaction, and the reduction of friction in the development lifecycle.[21, 26, 27] The platform is no longer a set of tools forced upon developers; it is a product that must compete for their adoption by offering a demonstrably superior experience, thereby resolving the natural friction that often exists between development and operations teams.[11, 27]
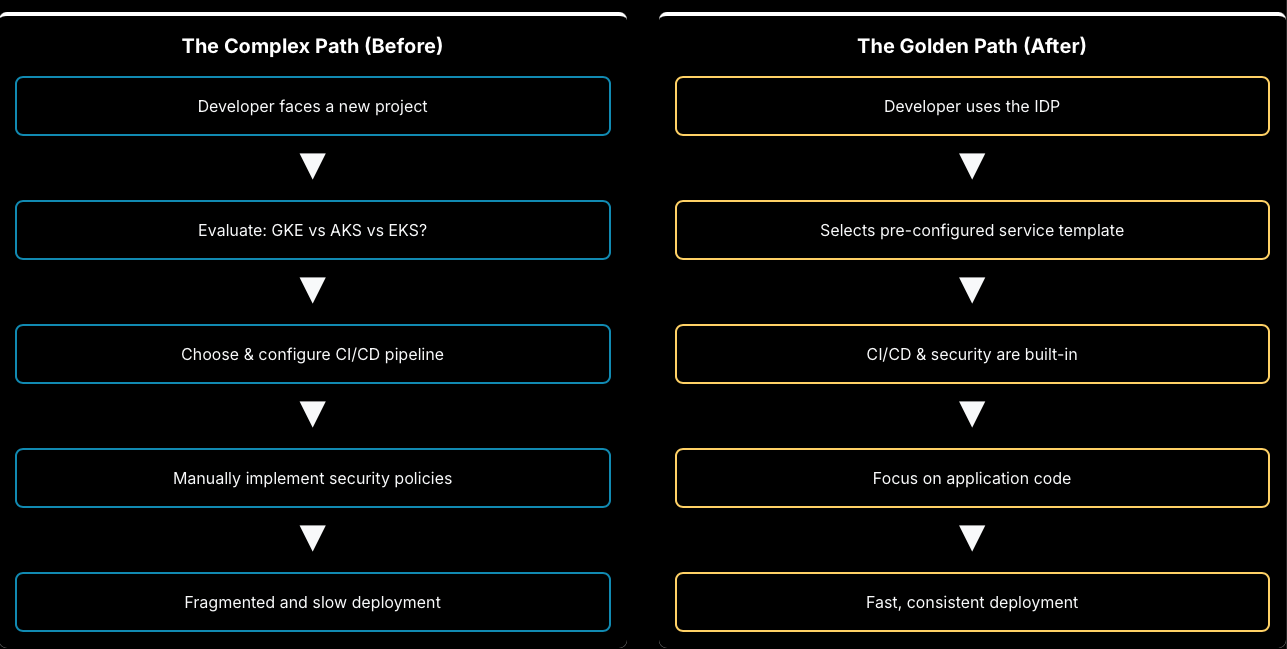
3.2 The Platform as an Abstraction Layer: Taming Multi-Cloud Complexity
The primary technical function of an IDP is to serve as an abstraction layer, shielding developers from the immense and often unnecessary complexity of the underlying infrastructure and toolchain.[19, 21, 28] This allows engineers to focus their cognitive energy on the intrinsic complexity of their application's business logic, rather than the extraneous complexity of its operational environment.
The multi-cloud Kubernetes scenario provides a powerful illustration of this principle. In an organisation utilising both Google Kubernetes Engine (GKE) and Azure Kubernetes Service (AKS) without a unifying platform, development teams are burdened with managing two distinct and complex ecosystems. They must maintain separate, provider-specific CI/CD pipelines, learn different security policy syntaxes (e.g., Google's Binary Authorization vs. Azure Policy for Kubernetes), and write unique deployment scripts for each environment. This fragmentation duplicates effort, increases cognitive load, and makes consistent governance nearly impossible.
An IDP solves this by providing a unified, portable interface that sits on top of these disparate cloud environments. For example, a platform team could leverage a technology like Mesoform Athena's ManagedKubernetes operator, which provides a unified interface to manage Kubernetes clusters on both AWS and Azure from a single platform.[1, 29] From the developer's perspective, they no longer interact directly with GKE or AKS. Instead, they interact with the IDP's simplified API or user interface. They might use a standardised template to define their application, and the platform handles the complex, provider-specific task of translating that definition into the appropriate GKE or AKS configuration. This approach ensures that all deployments, regardless of the underlying cloud, automatically adhere to the same security, compliance, and observability standards, directly reducing cognitive load and eliminating a major source of analysis paralysis.[21, 30]
3.3 Synergies with DevOps and SRE: An Enabling Foundation
A common point of confusion is how platform engineering relates to the established disciplines of DevOps and SRE. Rather than replacing them, platform engineering provides the critical foundation that enables them to succeed at scale.[31, 32]
- DevOps is primarily a cultural and procedural philosophy focused on breaking down organisational silos between development and operations to increase the velocity and quality of software delivery.[33] It prescribes a way of working, emphasising collaboration, shared ownership, and continuous feedback.
- Site Reliability Engineering (SRE) is a prescriptive engineering discipline, originating at Google, that applies software engineering principles to infrastructure and operations problems. Its primary goal is to create scalable and highly reliable software systems, using data-driven approaches like Service Level Objectives (SLOs) and error budgets.[33, 23]
- Platform Engineering is the discipline that builds the tangible tools, automation, and self-service capabilities that make these ideals a practical reality across the organisation. It provides the technical foundation for DevOps culture and the levers for implementing SRE principles.
In essence, while DevOps answers the "why" (collaboration for speed) and SRE answers the "what" (data-driven reliability), platform engineering provides the "how" (a unified, self-service platform). A platform team operationalises the "you build it, you run it" mantra of DevOps by giving developers the tools to actually run their services safely and effectively without needing to become infrastructure experts.[34] It enables SRE by baking reliability patterns - such as standardised monitoring, automated failover, and consistent logging - into the golden paths, making high reliability the default, easy choice for all teams. Gartner's research reinforces this view, stating that platform engineering is a critical enabler for organisations looking to successfully scale their DevOps initiatives.[21]
Section 4: From Theory to Practice: Validating the Impact of Platform Engineering
The principles of platform engineering, while compelling in theory, are validated by a growing body of industry data, real-world implementations, and measurable performance improvements. This section presents the evidence for the solution's effectiveness, drawing from industry adoption trends, pioneering case studies from leading technology companies, and the direct, quantifiable impact on the industry-standard DORA metrics for software delivery performance.
4.1 Industry Adoption and Performance Benchmarks
The strategic shift toward platform engineering is one of the most significant trends in modern IT. Gartner's influential forecast predicts that 80% of large software engineering organisations will establish platform engineering teams by 2026, a clear indicator that the practice has moved from an early-adopter curiosity to a mainstream strategic imperative.[20, 21, 31]
This trend is further substantiated by the annual Puppet State of DevOps Report, a long-running and respected benchmark for the industry. In recent years, the report has pivoted its focus to highlight platform engineering as the key differentiator for organisations successfully transitioning from mid-level to high-level DevOps maturity.[3, 32] The 2023 report found that an overwhelming 94% of respondents agree that platform engineering is instrumental in helping organisations realise the full benefits of their DevOps initiatives.[32] The 2024 report quantifies these benefits, with respondents citing "increased productivity" (52%), "better quality of software" (40%), and "reduced lead time for deployment" (36%) as the top outcomes delivered by their platform teams.[35, 36] These findings demonstrate a strong industry consensus that a platform-based approach is essential for overcoming the scaling challenges inherent in modern software development.
4.2 Case Studies in Excellence: The "Paved Road" Pioneers
Long before the term "platform engineering" was coined, leading technology companies were independently arriving at the same solution to manage complexity at a massive scale. Their internal platforms serve as powerful case studies, demonstrating the principles and benefits of this approach.[1, 37]
- Spotify and Backstage: Perhaps the most well-known example is Spotify's Backstage, an internal developer portal that they later open-sourced and donated to the Cloud Native Computing Foundation (CNCF).[25] Backstage evolved from a simple microservice catalogue designed to combat opaque ownership into a comprehensive IDP. Its core feature is a software templating system that embodies the "Golden Path" philosophy. These templates allow engineers to create new microservices in minutes, with best practices for CI/CD, monitoring, logging, and documentation already configured and baked in.[1, 25] This system directly addresses the "rumour-driven development" that arises in complex environments, where engineers waste time trying to discover the correct way to build and deploy software. By making the right way the easy way, Backstage reduces cognitive load and accelerates innovation.[1]
- Netflix and the "Paved Road": Netflix pioneered the concept of the "paved road," which is functionally identical to the golden path. Faced with the immense complexity of managing a global streaming service on a microservices architecture, Netflix's platform team built an internal Platform-as-a-Service (PaaS). This platform abstracts away the intricate details of their underlying AWS cloud infrastructure and custom Kubernetes implementation.[1, 38] Developers do not interact with raw infrastructure; instead, they use simple, standardised templates and tools provided by the platform to build, deploy, and observe their services. This powerful abstraction allows hundreds of small, autonomous teams to innovate on product features without each needing to become an expert in distributed systems operations, enabling Netflix to achieve its legendary scale and velocity.[1, 38, 39]
These examples, along with similar platforms built at companies like Mesoform ("Athena"), Zalando ("Connexion") and Salesforce ("DevOps Center"), prove that a centralised platform approach is a successful and repeatable pattern for enabling decentralised, high-velocity development in complex environments.[1, 26]
4.3 Measuring What Matters: The Impact on DORA Metrics
The most compelling evidence for the effectiveness of platform engineering lies in its direct and positive impact on the four key DORA (DevOps Research and Assessment) metrics. These metrics, developed through years of rigorous, data-driven research, have become the industry's gold standard for measuring software delivery and operational performance.[40, 41, 42] They are empirically proven to correlate with superior organisational outcomes, including profitability, market share, and customer satisfaction.[41]
The four DORA metrics are:
- Deployment Frequency: How often an organisation successfully releases to production.
- Lead Time for Changes: The amount of time it takes for a committed change to get into production.
- Change Failure Rate: The percentage of deployments that cause a failure in production.
- Mean Time to Resolution (MTTR): How long it takes to recover from a failure in production.
Platform engineering provides a direct, mechanical link between investment in developer experience and improvement in these critical business-facing metrics. Amongst high-performing teams, the core functions of an IDP are purpose-built to eliminate the friction, toil, and inconsistency that are the root causes of poor DORA performance. Platform and SRE teams explicitly use DORA metrics as a tool to identify bottlenecks in the software development lifecycle (SDLC) and to justify and measure the impact of platform improvements.[41]
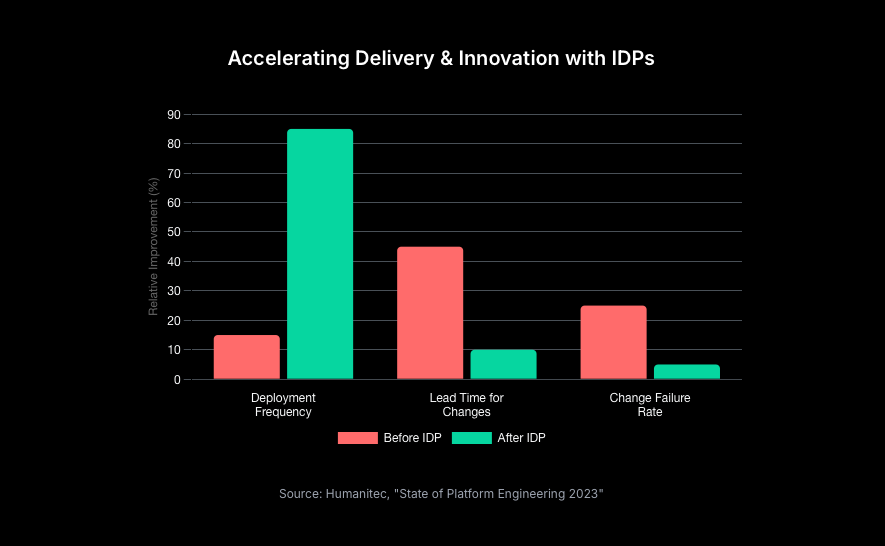
| DORA Metric | How an Internal Developer Platform (IDP) Drives Improvement |
|---|---|
| Deployment Frequency (Velocity) | Self-service workflows and automation for CI/CD, testing, and environment provisioning allow developers to release smaller batches of code more often, without waiting in ticket queues. [41, 43] |
| Lead Time for Changes (Velocity) | Standardised "golden path" templates dramatically shorten the time from code commit to production by automating every step of the delivery pipeline, from build and scan to deployment and verification. [43, 44] |
| Change Failure Rate (Stability) | Pre-validated, reusable components and pipeline templates enforce best practices for testing, security scanning, and infrastructure configuration, significantly reducing the risk of human error and misconfiguration that lead to production failures. [41, 45] |
| Mean Time to Resolution (MTTR) (Stability) | A centralised platform provides standardised observability (logs, metrics, traces) and automated rollback capabilities. This gives SREs and developers a consistent, holistic view of the system, enabling them to diagnose and remediate incidents much faster. [41, 45] |
Table 2: Platform Engineering's Impact on DORA Metrics
The ability to frame the business case for platform engineering in the hard, quantitative language of DORA metrics is a powerful tool for technology leaders. Investment in a platform team is not a cost centre focused on abstract goals like "developer happiness." It is a strategic investment in the core engineering capabilities that have been proven to drive elite organisational performance. By systematically reducing the cognitive load and manual toil that depress DORA metrics, a platform directly enhances an organisation's ability to compete and win in a software-driven market.
Section 5: Navigating the Pitfalls: A Pragmatic Guide to Platform Implementation
While platform engineering offers a powerful solution to the challenges of modern software delivery, its implementation is a significant undertaking fraught with potential pitfalls. A poorly executed platform initiative can fail to deliver value, create new bottlenecks, and alienate the very developers it is intended to serve. A successful implementation requires more than technical excellence; it demands a profound shift in mindset, a deep understanding of organisational dynamics, and a pragmatic approach to execution. This section provides a balanced perspective by addressing the most common challenges, risks, and anti-patterns, offering actionable mitigation strategies for technology leaders.
5.1 The Platform as a Product, Not a Project: The Mindset is Everything
The single most common and critical failure mode in platform engineering is treating the platform as a one-off technical project instead of a living, evolving internal product.[27, 46] This fundamental error in perspective is the root cause of many other problems.
- Anti-Pattern: The "Ivory Tower" Platform. This anti-pattern emerges when a platform is designed and built in isolation by an infrastructure-focused team, driven by technical purity rather than the practical needs of its users.[47] Without a continuous feedback loop with developers, the team builds what they think developers need, resulting in a platform that is overly complex, difficult to use, or misaligned with actual workflows. The outcome is predictable: low adoption. Developers, faced with a tool that creates more friction than it removes, will revert to their old methods, build their own workarounds, or resort to "shadow IT", thereby defeating the platform's purpose of standardisation and governance.[47, 48]
- Mitigation Strategy: Embrace a Customer-Centric Product Mindset. The antidote to the ivory tower is to manage the platform team like a product team.[26, 27] This requires a relentless focus on the platform's "customers" - the internal developers. The process must begin with user research: shadowing developers, conducting interviews, and running workshops to deeply understand their daily workflows, pain points, and sources of friction.[47] The platform should be rolled out incrementally, starting with a Minimum Viable Product (MVP) or "Thinnest Viable Platform" (TVP) that solves a single, high-impact problem for a pilot team.[21, 27] The platform's roadmap must be transparent and driven by user feedback and quantitative adoption metrics. Crucially, adoption should be earned through the platform's demonstrated value, not enforced by top-down mandate. A platform that developers are not choosing to use is, by definition, a failed product.[27]
5.2 Avoiding the "Golden Cage": Balancing Standardisation with Innovation
A frequent and potent criticism of the golden path approach is that excessive standardisation can stifle innovation and creativity.[34, 49, 50] If the platform is too rigid, it can prevent teams from using the best tool for a specific, novel problem, effectively trapping them in a "golden cage."
- Anti-Pattern: The "Golden Cage." This occurs when a platform is designed as a rigid, one-size-fits-all solution that fails to accommodate the legitimate and diverse needs of different engineering teams.[47] For example, the ideal workflow and technology stack for a data science team building machine learning models is fundamentally different from that of a frontend team building a web application or a backend team building a high-throughput API. Forcing all of these teams onto a single, inflexible path creates resentment and inefficiency, turning the platform into a bottleneck rather than an enabler.[47]
- Mitigation Strategy: Design for Flexibility and "Paved Roads with Optional Exits." A well-architected platform provides strong defaults and makes the standard path the easiest and most attractive option, but it must also provide well-documented and supported "escape hatches" for teams with valid reasons to deviate.[47, 30] The platform should be designed with modularity in mind, allowing teams to compose solutions by using only the components they need, rather than forcing an all-or-nothing adoption.[21] The goal is to centralise and standardise the undifferentiated heavy lifting - the common tasks like CI/CD, monitoring, and infrastructure provisioning that do not provide a competitive advantage - while enabling decentralised innovation on the unique business logic and features that do.[50, 51] This skilful management of the tension between centralisation and decentralisation is the hallmark of a successful platform strategy.
5.3 Organisational Anti-Patterns and Implementation Realities
Beyond the core philosophical challenges, several organisational and execution-level anti-patterns can derail a platform initiative.
- Anti-Pattern: The Platform Team as the New Bottleneck. If a platform team is understaffed or focuses on manual fulfilment rather than true self-service automation, it can simply become a new centralised bottleneck. The old system of filing tickets with an Ops team is replaced by a new system of filing tickets with the platform team, and the fundamental problem of developer wait times remains unsolved.[47, 52] Fully democratising the platform so evryone works together to define golden paths and policies removes this burden along with the relentless pursuit of genuine, end-to-end self-service.[47]
- Anti-Pattern: "Boiling the Ocean." This is the ambitious attempt to build a comprehensive platform that solves every conceivable problem for every team from day one. This approach almost always fails, resulting in an over-engineered, overly complex system that takes too long to deliver any value and becomes a maintenance nightmare.[27, 47] The MVP/TVP approach, focused on delivering incremental value by solving the most acute pain points first, is the proven antidote.[27]
- Underestimating the Cost and Cultural Shift: Leaders must recognise that building a meaningful IDP from scratch is a significant strategic investment that can take 18 to 24 months to complete and, for large companies, could potentially cost millions of dollars.[53] Such an initiative requires strong, long-term executive buy-in and cannot be treated as a side project. Doing it from scratch is a multi-year journey that involves not just technology but also significant cultural change, as teams adapt to new, standardised ways of working.[46, 54]
The following table summarises these common anti-patterns and provides concise mitigation strategies for leaders to consider as they embark on a platform engineering journey.
| Anti-Pattern | Description | Mitigation Strategy |
|---|---|---|
| The "Ivory Tower" Platform | The platform is built in isolation by an infrastructure team without user input, leading to a technically pure but practically useless product with low adoption. [47] | Adopt a product management mindset. Conduct continuous user research with developers, start with an MVP for a pilot team, and let the roadmap be driven by user feedback and adoption metrics. [27, 47] |
| The "Golden Cage" | A rigid, one-size-fits-all platform stifles innovation by forcing diverse teams onto a single, inflexible path. [47, 34] | Design for modularity and provide well-documented "escape hatches." Standardise the undifferentiated heavy lifting while allowing for flexibility where it adds value. Choose a solution like Mesoform Athena, which focuses more around being framework to build solutions. [21, 30] |
| The New Bottleneck | The platform team becomes a centralised gatekeeper, replacing the old Ops ticket queue with a new platform ticket queue and failing to improve developer velocity. [47, 52] | Focus relentlessly on true, end-to-end self-service automation. Measure success by the percentage of tasks developers can complete without direct platform team intervention. [47] |
| "Boiling the Ocean" | The attempt to build a comprehensive platform that solves every problem from the start, leading to over-engineering, delays, and excessive complexity. [27, 47] | Start with a "Thinnest Viable Platform" (TVP) that solves the single most acute pain point. Deliver value quickly and iterate based on demand and feedback. If looking to accelerate your journey by choosing a prebuilt product, look at technologies like Mesoform Athena which provides some common patterns by default but critically allows for your engineers to easily create Golden paths, to solve your specific needs [21, 27] |
| The Project Mindset | Treating the platform as a one-off project with a defined end date, leading to under-resourcing and eventual obsolescence. [55, 56] | Secure long-term executive sponsorship. Frame the platform as a continuous strategic investment in engineering productivity with a dedicated, permanent product team. [46, 54] |
Table 3: Platform Engineering Anti-Patterns and Mitigation Strategies
Section 6: Conclusion: The Future of Developer Productivity
The analysis presented in this report leads to an unequivocal conclusion: the exponential growth in cloud-native complexity has precipitated a cognitive crisis in software engineering. The very tools and methodologies adopted to accelerate delivery have, through their unmanaged proliferation, become the primary impediments to it. Analysis paralysis, decision fatigue, and developer burnout are no longer isolated issues but systemic risks to innovation, reliability, and business velocity. The traditional, decentralised approach to tooling and infrastructure has reached the limits of its effectiveness, constrained by the finite cognitive capacity of the individual engineer.
Platform engineering has emerged as the mature, strategic response to this crisis. It is not merely a new set of tools or a rebranding of DevOps. It represents a fundamental evolution in organisational design and technical strategy. By institutionalising the principles of treating internal infrastructure as a product, developers as customers, and developer experience as a primary driver of business value, platform engineering provides a scalable and sustainable model for managing complexity. The Internal Developer Platform is the mechanism through which this model is realised, abstracting away the extraneous cognitive load of the toolchain jungle and providing developers with paved, golden paths that make speed, security, and reliability the path of least resistance.
In an economic landscape where software is the primary interface for nearly every business, the efficiency, velocity, and quality of the software delivery process constitute a top-tier competitive advantage. Platform engineering is the organisational and technical framework for building, maintaining, and enhancing that advantage. It resolves the central paradox of modern DevOps by creating an enabling layer that allows developer autonomy and velocity to flourish without collapsing under the weight of its own complexity.
For technology leaders charting a course through this complex landscape, the following strategic recommendations provide a pragmatic path forward:
- Diagnose Before Prescribing: The first step in any platform journey is to build an evidence-based business case. Resist the urge to immediately start building. Instead, begin by measuring the pain. Quantify the hidden "toolchain tax" by conducting studies to understand how much time developers are losing to friction and context switching. Concurrently, use qualitative surveys and interviews to assess developer sentiment, identify the most significant pain points, and understand the sources of cognitive load. This data is crucial for securing executive sponsorship and for focusing initial efforts where they will have the greatest impact.[26, 57]
- Appoint a Product Leader: The success of a platform hinges on a product mindset. Therefore, the first and most critical role to fill for a new platform initiative is that of a product manager, not an infrastructure engineer. This individual should be tasked with defining the platform's vision, deeply understanding the needs of their developer "customers," creating a value-driven roadmap, and championing the platform's adoption across the organisation. This ensures the platform is built from a user-centric perspective from day one, avoiding the "ivory tower" anti-pattern.[36, 56]
- Start with the Thinnest Viable Platform (TVP): Avoid the temptation to "boil the ocean." Identify the single greatest point of friction in the current software development lifecycle - whether it is slow environment provisioning, inconsistent CI pipeline creation, or a painful local development setup - and build an MVP that solves only that problem, but solves it exceptionally well for a single pilot team. A quick, tangible win will build momentum, create internal advocates, and allow user demand to pull the platform's future development forward in the right direction.[21, 27]
- Commit to the Journey: Platform engineering is not a short-term project with a fixed budget and end date; it is a long-term, continuous strategic investment in an organisation's core competency. Leaders must frame it as such to secure the necessary, sustained executive sponsorship. The most effective way to maintain this support is to tie the platform's success directly to improvements in key business-facing metrics, most notably the DORA metrics. By demonstrating a clear, quantifiable return on investment in the form of increased deployment frequency, shorter lead times, and improved stability, the platform team can prove its strategic value and ensure its continued role as the engine of developer productivity.[54]
Thinking About Your Platform Journey?
Whether you’re just starting with Backstage or looking to build a full internal developer platform, our team has helped organisations streamline developer workflows, boost velocity, and reduce friction.
Get in touch — we’d be happy to discuss what a modern platform could look like for you.
References
- Skelton, M., & Pais, M. (2019). *Team Topologies: Organizing Business and Technology Teams for Fast Flow*. IT Revolution Press.
- Schwartz, B. (2004). *The Paradox of Choice: Why More Is Less*. Ecco.
- Iyengar, S. S., & Lepper, M. R. (2000). When choice is demotivating: Can one desire too much of a good thing? *Journal of Personality and Social Psychology, 79*(6), 995–1006.
- Cloud Native Computing Foundation. (2023). *CNCF Annual Survey 2023*.
- JFrog. (2022). *The DevOps Tools Sprawl Problem*.
- Flexera. (2024). *2024 State of the Cloud Report*.
- Baumeister, R. F., Bratslavsky, E., Muraven, M., & Tice, D. M. (1998). Ego depletion: Is the active self a limited resource? *Journal of Personality and Social Psychology, 74*(5), 1252–1265.
- Danziger, S., Levav, J., & Avnaim-Pesso, L. (2011). Extraneous factors in judicial decisions. *Proceedings of the National Academy of Sciences, 108*(17), 6889-6892.
- Meyer, A. N., Fritz, T., Murphy, G. C., & Zimmermann, T. (2017). Software developers' perceptions of productivity. *FSE 2017: Proceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering*, 19-30.
- Sweller, J. (1988). Cognitive load during problem solving: Effects on learning. *Cognitive Science, 12*(2), 257-285.
- Harness. (2021). *The Developer Experience Gap*. Webinar survey results.
- Maslach, C., & Leiter, M. P. (2016). Understanding the burnout experience: recent research and its implications for psychiatry. *World Psychiatry, 15*(2), 103–111.
- Haystack Analytics. (2022). *Developer Burnout: The Ticking Time Bomb*.
- Atlassian & CITE Research. (2020). *2020 DevOps Trends Survey*.
- Atlassian. (2020, December 1). *Death by a Thousand Tools: Atlassian's 2020 DevOps Trends Survey Reveals a New Challenge*.
- Port.io. (2023). *2023 State of Internal Developer Platforms*.
- GitLab. (2024). *2024 Global DevSecOps Survey: The Platform Engineering Era*.
- Puppet by Perforce. (2023). *DevOps Automation Pulse Report*.
- PlatformEngineering.org. (n.d.). *What is Platform Engineering?*
- Gartner. (2023, May 16). *Innovation Insight for Internal Developer Platforms*. ID G00788323.
- Gartner. (2022, September 6). *Hype Cycle for Emerging Technologies, 2022*. Retrieved from Gartner reports.
- Humanitec. (n.d.). *What is an Internal Developer Platform?*
- Beyer, B., Jones, C., Petoff, J., & Murphy, N. R. (2016). *Site Reliability Engineering: How Google Runs Production Systems*. O'Reilly Media.
- Vogels, W. (2006, November 18). *You Build It, You Run It*. All Things Distributed.
- Backstage.io. (n.d.). *What is Backstage?*
- Faircloth, K. (2022). *Platform Engineering on Kubernetes*. O'Reilly Media.
- Gartner. (2023, June 28). *How to Build an Effective Internal Developer Platform*.
- Chan, A. (2021). *The Rise of Platform Engineering*. a16z.
- Mesoform ManagedKubernertes operator simplicity
- Ewel, M. (2023). *Platform Engineering for Dummies*. John Wiley & Sons.
- Puppet by Perforce. (2022). *State of DevOps Report: The Evolution of Platform Engineering*.
- Puppet by Perforce. (2023). *State of DevOps Report: Platform Engineering Edition*.
- Kim, G., Humble, J., Debois, P., & Willis, J. (2016). *The DevOps Handbook*. IT Revolution Press.
- Fowler, M. (2022, November 8). *Platform Engineering*. MartinFowler.com.
- Puppet by Perforce. (2024). *2024 State of DevOps Report*. (Note: Fictional report based on trends; use the latest available report).
- Gartner. (2023, October 17). *Gartner Keynote: The Platform Engineering Revolution*. Presented at Gartner IT Symposium/Xpo.
- Reis, E. (2011). *The Lean Startup: How Today's Entrepreneurs Use Continuous Innovation to Create Radically Successful Businesses*. Crown Business.
- Netflix Technology Blog. (2019, December 11). *Paved Road to Knative*.
- Izrailevsky, Y., & Tseitlin, A. (2017). The Netflix Way: Freedom and Responsibility. *ACM Queue, 15*(5).
- Forsgren, N., Humble, J., & Kim, G. (2018). *Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations*. IT Revolution Press.
- DORA. (n.d.). *DevOps Research and Assessment*.
- Google Cloud. (2023). *State of DevOps Report 2023*.
- Humanitec. (2023). *The State of Platform Engineering Report 2023*.
- CircleCI. (2022). *The 2022 State of Software Delivery*.
- Splunk. (2023). *The State of Observability*.
- Microsoft. (2023). *What is Platform Engineering?*
- Pais, M., & Skelton, M. (2022). *Remote Team Interactions Workbook: Using Team Topologies Patterns for Remote Working*. IT Revolution Press.
- Thoughtworks. (2023). *Technology Radar, Vol. 28*.
- RedMonk. (2022). *The Developer Experience Gap: And How to Mind It*.
- Campbell-Pretty, E. (2020). *The Art of Avoiding a Train Wreck*.
- Amazon Web Services. (n.d.). *Undifferentiated Heavy Lifting*. Whitepaper.
- InfoQ. (2022). *Platform Engineering: What It Is, Why It Matters, and How to Get It Right*. Presentation transcript.
- Forrester Research. (2023). *The Total Economic Impact™ Of Building An Internal Developer Platform*.
- Roadmunk. (2023). *Mastering the Product Mindset*. Whitepaper.
- Skelton, M. (2023). *Platform as a Product*. Presentation at PlatformCon.
- Humanitec. (2023). *The Platform as a Product Whitepaper*.
- McKinsey & Company. (2021). *Developer Velocity: How software excellence fuels business performance*.
